
LLMOにおける構造化データ(schema.org/JSON-LD)の役割は、AIに「このページが誰の・何の情報か」を機械可読な形で正確に伝え、AI回答に引用されやすいチャンクへ整形することです。結論から言えば、最優先はOrganization・Article・FAQPage・BreadcrumbListの4種schemaの実装で、なかでもFAQPage schemaは独立調査でAI引用率+30〜40%の示唆がある最効率の施策です。ただし構造化データは「下支え役」であり、AI引用を本格的に増やすには外部評価獲得(掲載営業・関連被リンク・業界比較サイト掲載)との組み合わせが不可欠です。
本記事では、2026年6月時点の最新動向を踏まえ、LLMO 構造化データで実装すべき4種schema・JSON-LDの実装手順・FAQ/HowTo schemaの活用法・やってはいけないNG例・構造化データだけで完結しない理由までを、BtoBの実装担当者がそのまま使える粒度で解説します。
「構造化データの実装からAIに引用される外部評価獲得まで一気通貫で進めたい」という方は、Mesutの無料相談をご活用ください。被リンク施策20社以上・コスメメディア350万PV構築の知見をもとに、貴社の状況に合わせた優先順位をその場でお伝えします。
LLMO構造化データとは|AIに「意味」を伝えるマークアップ
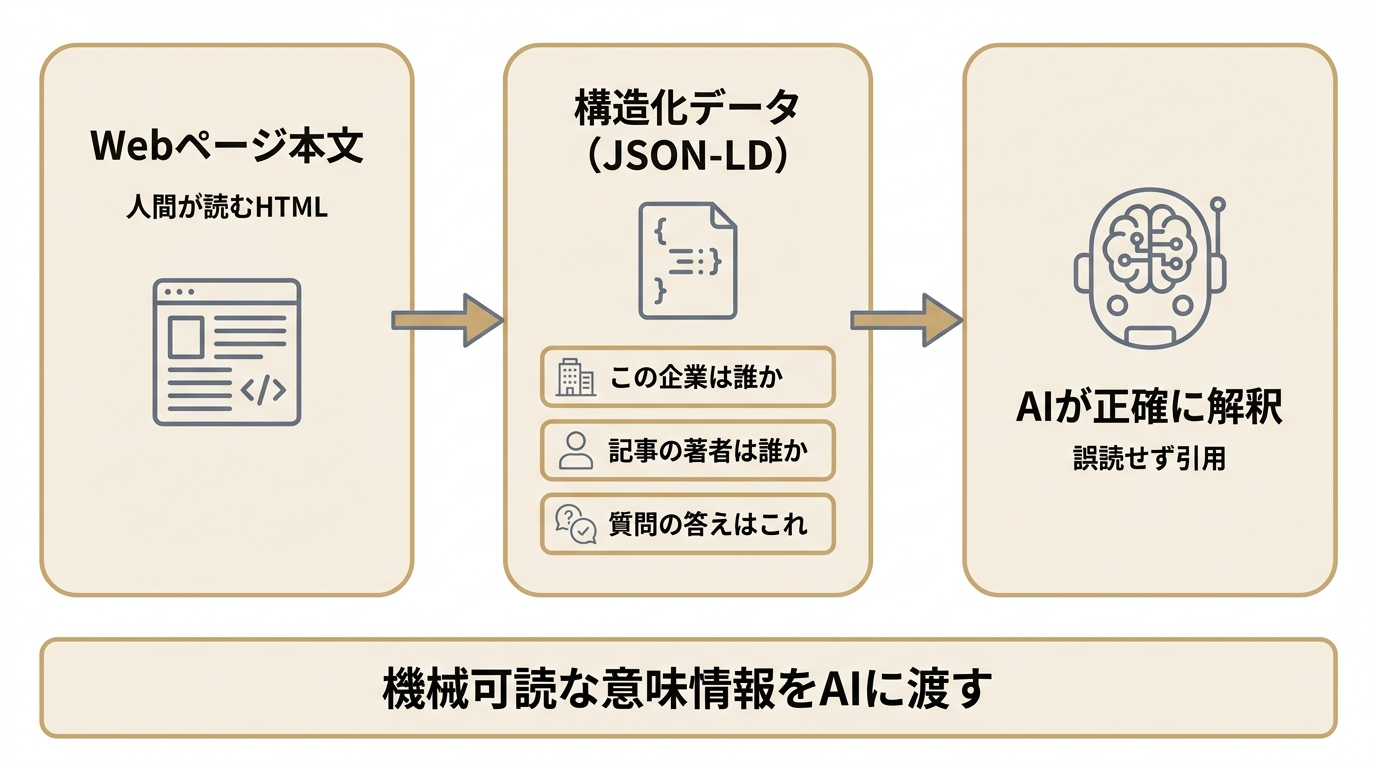
LLMO 構造化データとは、Webページの内容をschema.orgの語彙に沿ってJSON-LD形式でマークアップし、AI・検索エンジンに「機械可読な意味情報」を渡す技術です。人間が読むHTML本文とは別に、「この企業は誰か」「この記事の著者は誰か」「この質問の答えはこれ」といった構造を明示することで、AIがページ内容を誤読せず正確に解釈できるようになります。

構造化データがLLMOで効く3つの理由
LLMO(大規模言語モデル最適化)の観点で構造化データが持つ効果は、大きく次の3つに整理できます。
- エンティティ認識の精度向上:Organization schemaで「この企業が何者か」を明示し、AIの知識グラフ上で企業を正しい実体として認識させる
- FAQ/HowTo抽出のしやすさ:質問と回答・手順が構造化されることで、AI回答のチャンクとして切り出され引用されやすくなる
- 著者情報のクロスバリデーション:Person schemaで執筆者・監修者の専門性を明示し、E-E-A-T(経験・専門性・権威性・信頼性)の信頼シグナルを強化する
SEOのリッチリザルトとLLMO引用の違い
従来のSEOでは、構造化データは主に検索結果のリッチリザルト(星評価・FAQ展開・パンくず表示など)を目的に実装されてきました。Googleの公開事例では、リッチリザルト対応ページでCTRが25〜82%向上したケースも報告されています。一方LLMOでは、リッチリザルトの見た目より「AIがページの意味と権威性を正確に把握し、回答生成時の引用元として選ぶか」が焦点になります。同じschemaでも、目的とゴールが異なる点を押さえておきましょう。

LLMO対策で実装すべき4種schemaと優先順位

LLMO 構造化データで最初に実装すべきは、汎用性が高く効果が見込めるOrganization・Article・FAQPage・BreadcrumbListの4種です。それぞれの用途とLLMO効果を一覧で示します。
| schema種別 | 用途 | LLMO効果 | 優先度 |
|---|---|---|---|
| Organization | 法人情報(社名・所在地・代表者・SNS) | エンティティ認識の土台 | 最優先 |
| FAQPage | 質問と回答の構造化 | 引用率+30〜40%の示唆 | 最優先 |
| Article | 記事メタ(タイトル・著者・公開日・更新日) | 記事単位の権威性シグナル | 高 |
| BreadcrumbList | パンくずでの階層構造 | AIへの構造的理解の補助 | 中 |
Organization schemaがエンティティ認識の土台になる理由
Organization schemaは、AIが「この企業は実在するどの法人か」を判定するための基礎情報です。name・url・logo・sameAs(SNS・Wikipediaへのリンク)を正確に記述することで、AIは複数の情報源を突き合わせて企業を一意のエンティティとして認識します。LLMOで企業名やサービス名で引用されたい場合、まず最初に固めるべきはこのOrganization schemaです。
Person schemaの追加でE-E-A-Tを補強する
4種に加えてPerson schema(執筆者・監修者)を実装すると、特にYMYL(健康・金融など人生に影響する領域)での信頼シグナルが強化され、YMYL領域での引用率+40%の示唆もあります。著者のname・jobTitle・専門資格・所属(worksFor)をschemaとプロフィールページの双方で一致させ、AIが著者の専門性をクロスバリデーションできる状態にしておきます。
JSON-LDでのLLMO構造化データ実装手順
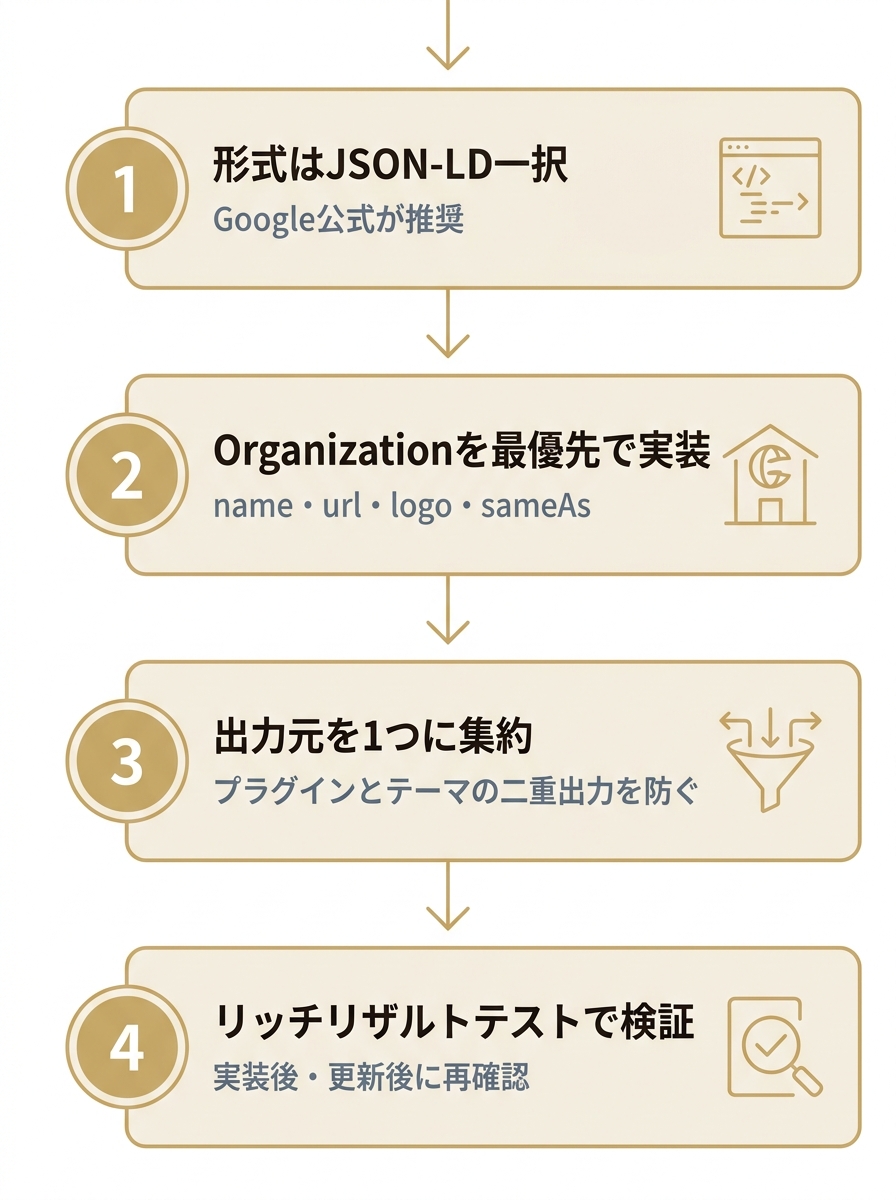
LLMO 構造化データの実装形式は、Google公式が明確に推奨するJSON-LD一択です。Googleは「JSON-LDはサイトオーナーが大規模に実装・保守しやすい最も簡単な形式」と公式に発言しており、保守性・可読性の両面でmicrodataやRDFaより優位です。
Organization schemaに含めるべきプロパティ
Organization schemaの実装では、最低限以下のプロパティを揃えます。Googleの指針どおり「数を網羅するより、少数でも正確で完全な記述」を優先してください。
- name:正式な法人名(表記ゆれを避け統一する)
- url:公式サイトのトップURL
- logo:ロゴ画像の絶対URL
- address:所在地(postalAddressで構造化)
- contactPoint:問い合わせ窓口(電話・メール・対応言語)
- sameAs:SNS・Wikipedia・各種プロフィールへのリンク群(エンティティ統合の鍵)
- founder/foundingDate:任意だが権威性の補強に有効
WordPressでの実装方法(プラグイン vs 手動)
WordPressの場合、SEO総合プラグイン(Yoast SEO/Rank Math/All in One SEO/SEO SIMPLE PACK)でOrganization・Article・BreadcrumbListの大半は自動出力できます。テーマ独自の構造化データ機能と併用するとschemaが二重に出力されエラー判定の原因になるため、出力元はどれか1つに集約してください。プラグインでカバーできないカスタムschemaが必要な場合のみ、<head>内に手動でJSON-LDを記述し、実装後に必ずリッチリザルトテストで検証します。
FAQPage schemaの活用|LLMO引用率向上の決め手
FAQPage schemaは、独立調査でAI引用率+30〜40%の示唆がある、LLMO 構造化データのなかで最も費用対効果の高い施策です。質問と回答が明確に構造化されることで、AIが回答生成時にそのまま引用しやすい「自律的チャンク」になります。
引用されるFAQ schemaの設計ポイント
- 実際の商談・問い合わせで出る質問のみに絞る(架空の質問は引用されにくく信頼も損なう)
- 1記事あたり3〜10問程度を目安にする(詰め込みすぎはNG)
- 回答は40〜60語で完結する自律的チャンクに整形する(前提なしで意味が通る形にする)
- 本文中のFAQセクションとschemaの内容を完全に一致させる
FAQ schemaのリッチリザルトとLLMO引用の関係
注意点として、Google検索のFAQリッチリザルト表示は現在、政府・医療系など一部サイトに限定されています。つまり検索結果での見た目の変化は期待しづらい状況です。一方で、FAQの構造化自体はAIが回答を抽出する際の手がかりとして依然有効であり、「見た目のリッチリザルト」ではなく「AI引用のためのチャンク整形」として実装する、という目的の捉え直しが重要です。
HowTo schemaの活用|手順系コンテンツのLLMO構造化
HowTo schemaは「○○のやり方」「△△の設定手順」型コンテンツに有効で、AI回答内で「ステップ1〜N」の形で抽出されやすくなります。手順を明示することで、AIが操作プロセスを正確に再現した回答を生成しやすくなる点がLLMO上のメリットです。
HowTo schemaが向くコンテンツ・向かないコンテンツ
HowTo schemaが向くのは、「明確な順序があり、各ステップが独立して説明できる」操作・設定・申込みフローなどです。逆に、順序が前後しうる概念解説や、ステップ化すると意味が崩れる戦略論には不向きです。無理にHowTo化するより、Article+FAQの組み合わせで構造化したほうが引用されやすいケースもあります。
HowTo実装時の注意点
各ステップにname(手順名)とtext(具体的な操作内容)を必ず含め、本文の手順表記と一致させます。画像を伴う手順ではimageを付与すると抽出精度が上がります。なお、HowToのリッチリザルトもGoogle検索では縮小傾向にあるため、ここでも「AIへの構造伝達」を主目的と捉えて実装するのが適切です。
構造化データ実装でやってはいけない3つのこと
LLMO 構造化データは、誤った実装をすると効果が出ないどころか評価を下げる要因にもなります。特に避けるべき3点を挙げます。
本文と乖離したFAQ schemaの大量投入
引用率を狙って本文に存在しない質問を大量にschemaへ詰め込むのは典型的なNGです。本文とschemaの内容が乖離するとスパム判定の対象になり、ページ全体の信頼性を損ないます。schemaは「本文を構造化したもの」であるべきで、schemaのために本文と無関係な情報を作るのは本末転倒です。
schema出力の重複とテスト省略
- schema出力プラグイン/テーマ機能を2系統以上有効化する:同一schemaが重複出力され、Googleがエラー・矛盾と判定する
- 検証ツールでのテストを省略する:1文字のミスでschema全体が無効化されても気づけない
- 実装後の継続監視を怠る:テーマ更新やプラグイン変更で出力が壊れるケースがある
構造化データだけでLLMO対策が完結しない理由
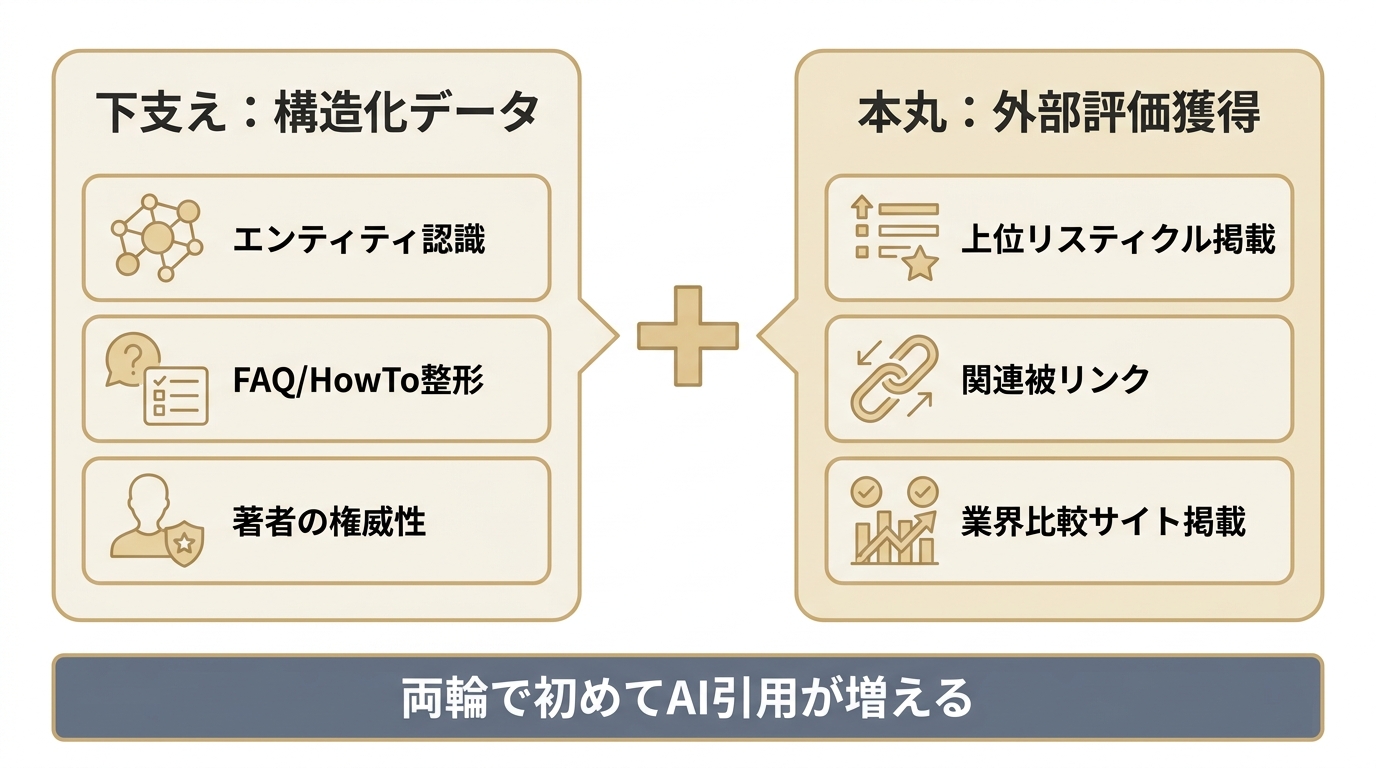
ここまで構造化データの実装を解説してきましたが、最も重要な前提を明確にします。構造化データはあくまで「下支え役」であり、これ単体でAI引用が大きく増えるわけではありません。Google公式も「AI Overviewsに出るための特別なschemaは不要」と明言しています。
AI引用の本丸は「外部評価獲得」
AIが回答の引用元を選ぶ際に重視するのは、「第三者からどれだけ評価・参照されているか」です。具体的には次の3つが本丸になります。
- 上位リスティクル・比較記事への掲載:AIが業界の選択肢を提示する際の引用元になる
- 関連性の高いドメインからの被リンク:エンティティとしての権威性を底上げする
- 業界比較サイト・カオスマップへの掲載:業界文脈の中で企業が言及される機会を作る
schemaを完璧に実装しても、これら外部評価が伴わなければAI引用は構造的に増えません。「構造化データで土台を整え、外部評価獲得で引用を取りにいく」という両輪で初めて成果が出ます。
Mesutが提供する一気通貫の実行支援
Mesutは、構造化データの実装指示書作成から外部評価獲得(掲載営業・被リンク営業)までを一気通貫で支援します。被リンク施策で20社以上を支援し、コスメメディアを18ヶ月で月間350万PVに成長させた実績をもとに、貴社が「いま何を優先すべきか」を明確にします。
| 支援領域 | 具体作業 |
|---|---|
| LLMO対策改善指示書 | 4種schema+Person schemaの実装指示 |
| FAQ/HowTo構造化指示 | 本文と整合する質問群の選定+schema化 |
| PR施策(カオスマップ等) | 業界カオスマップ作成・比較サイト掲載交渉 |
| 被リンク営業 | 関連性の高いドメインからの被リンク獲得 |
| 掲載営業 | 上位リスティクル記事への掲載交渉 |
執筆・監修:宇田晃平(株式会社Mesut)/SEO検定1級・YMAA認証。被リンク施策で20社以上を支援、コスメメディアを18ヶ月で月間350万PVに成長させた実務経験を持つ。本記事は、構造化データのリッチリザルト目的とLLMO引用目的の違いを実装現場の視点から整理し、schema実装だけで止まらず外部評価獲得まで含めた成果設計を解説しています。
LLMO構造化データに関するよくある質問
Q. 構造化データだけでAI引用は増えますか?
A. 効果は限定的です。FAQ schemaは引用率+30〜40%の示唆がありますが、Google公式も「AI Overviewsに特別なschemaは不要」と発言しています。構造化データは下支え役であり、外部評価獲得(掲載営業・関連被リンク・業界比較サイト掲載)が本丸です。両輪で進めて初めて引用が安定して増えます。
Q. JSON-LDとmicrodataはどちらがよいですか?
A. JSON-LDが推奨です。Google公式も「大規模に実装・保守しやすい最も簡単な形式」として明確に推奨しており、保守性・可読性でmicrodataより優位です。新規実装は迷わずJSON-LDを選んでください。
Q. 構造化データの実装をテストする方法は?
A. Google公式の「リッチリザルトテスト」と「スキーマ マークアップ検証ツール(Schema Markup Validator)」で検証できます。実装後は必ずテストしてエラー・警告の有無を確認し、テーマ更新後も定期的に再検証してください。
Q. FAQ schemaは何問入れるべきですか?
A. 1記事あたり3〜10問程度が目安です。本文と乖離した質問を大量に詰め込むとスパム判定の対象になります。実際の商談・問い合わせで出る質問のみに絞り、回答は40〜60語で完結する形に整形しましょう。
Q. schema出力プラグインは複数併用してよいですか?
A. 併用は避けてください。SEOプラグインとテーマ機能などで同一schemaが二重出力されると、Googleが矛盾・エラーと判定します。出力元はどれか1系統に集約し、それ以外の自動出力はオフにするのが安全です。
関連記事
まとめ|LLMO構造化データは「下支え+外部評価獲得」のセットで効く
LLMO 構造化データの要点を改めて整理します。
- 実装すべきは4種schema:Organization/FAQPage/Article/BreadcrumbList+Person
- FAQPage schemaは引用率+30〜40%の示唆がある最効率施策。ただし本文と一致させる
- 実装形式はJSON-LD一択。実装後はリッチリザルトテストで必ず検証する
- schemaの重複出力・本文乖離・テスト省略は避ける
- 構造化データは下支え役。本丸は外部評価獲得(掲載営業・関連被リンク・業界比較サイト掲載)
2026年6月時点でも、AI引用を本格的に増やすには「構造化データで土台を整え、外部評価獲得で引用を取りにいく」両輪が不可欠です。Mesutは、構造化データの実装指示からPR・被リンク・掲載営業までを一気通貫で支援します。まずは現状の課題と優先順位を整理する無料相談からお気軽にご相談ください。
関連記事




